Conhecendo o Negócio e o Programa de Fidelidade Insiders: Como Algoritmos de Agrupamento Podem Impulsionar Resultados
Nos últimos anos, com o avanço da análise de dados e o crescente volume de informações disponíveis, surgiram novas oportunidades para personalizar a experiência dos clientes e aumentar o faturamento de empresas em diferentes setores. Vamos conhecer o caso de uma equipe de marketing que, ao observar o comportamento de seus clientes, identificou uma oportunidade valiosa: um programa de fidelidade chamado Insiders para clientes especiais, com suporte do time de dados na seleção dos participantes.
1. Questão de Negócio: Selecionando os Clientes Ideais
Após pouco mais de um ano de operação, o time de marketing percebeu que alguns clientes compram com regularidade produtos de maior valor, contribuindo significativamente para o faturamento da empresa. Com esses insights, surgiu a ideia de lançar o programa Insiders para premiar e fidelizar esses clientes valiosos. No entanto, a equipe de marketing carecia de conhecimento avançado em análise de dados para identificar os participantes ideais para o programa.
1.1. Objetivo do Programa Insiders
O time de marketing espera que o programa não só aumente a frequência de compras desses clientes, mas também gere um impacto positivo no faturamento. Com isso em mente, algumas perguntas-chave precisam ser respondidas:
- Quem são as pessoas elegíveis para participar do programa?
- Quantos clientes farão parte do grupo?
- Quais as características desses clientes e sua contribuição para o faturamento?
- Qual a expectativa de faturamento desse grupo para os próximos meses?
- Quais são as condições de elegibilidade e exclusão do programa?
Essas questões formam a base para um relatório completo, orientado a dados, que ajudará o time de marketing a compreender e atingir os objetivos do programa Insiders.
2. Entendendo os Dados
Para responder a essas perguntas, a equipe de dados utilizou informações de compras feitas no e-commerce durante um ano, entre novembro de 2015 e dezembro de 2017. Os dados incluíam:
- InvoiceNo: Número de identificação da fatura
- StockCode: Código de estoque do produto
- Description: Descrição do produto
- Quantity: Quantidade de itens comprados
- InvoiceDate: Data da fatura
- UnitPrice: Preço unitário do produto
- CustomerID: Código de identificação do cliente
- Country: País da compra
Premissas de Negócio
Para criar o grupo ideal, o time de dados excluiu alguns clientes com comportamentos indesejáveis (como devolução de todas as compras) e produtos que não geravam valor, como brindes com preço inferior a £0,04.
3. Planejamento da Solução
A solução foi dividida em três etapas principais:
3.1. Produto Final
O objetivo final inclui uma lista com os clientes selecionados para o programa Insiders e um relatório com insights que respondem às perguntas de negócio. Além disso, foi implementado um sistema para classificar novos clientes em clusters específicos e integrar essas informações em um banco de dados Postgres. O acesso aos dados e visualizações é feito através de dashboards no Power BI.
3.2. Processo
- Entendimento do Problema: Alinhar a necessidade de agrupar clientes para o time de marketing.
- Coleta e Limpeza de Dados: Preparar os dados, identificando colunas essenciais, removendo inconsistências e criando identificadores únicos para faturas.
- Feature Engineering e EDA (Exploração dos Dados): Extrair variáveis relevantes para a modelagem e explorar o comportamento dos dados.
- Modelagem de Machine Learning: Aplicar técnicas de clusterização para agrupar clientes com base em comportamentos semelhantes.
- Análise dos Clusters e Avaliação dos Modelos: Utilizar a métrica Silhouette Score para avaliar os clusters e definir o número ideal de grupos (neste caso, nove clusters foram selecionados para simplificar o trabalho do time de marketing).
3.3. Ferramentas
Entre as principais ferramentas utilizadas estão Python, SQL (SQLite e PostgreSQL), Amazon Web Services (S3, RDS e EC2) e Power BI para visualização de dados.
4. Modelos de Machine Learning: Otimizando a Clusterização
A equipe utilizou técnicas de redução de dimensionalidade para melhorar o espaço de dados, como PCA, t-SNE e UMAP/Random Forest, focando no faturamento bruto para o treinamento da árvore de decisão. Entre os modelos testados, destacam-se:
- K-Means
- Gaussian Mixture Models (GMM)
- Hierarchical Clustering (HC)
- DBSCAN
O modelo K-Means foi escolhido, com um Silhouette Score de 0,585317, um valor satisfatório para a criação dos clusters. Para saber mais sobre o que é o score de silhueta e como esse valor é usado em machine learning, acesse meu GitHub no link no final do artigo.
5. Resultados de Negócio e Insights dos Clusters
Com os clusters formados, surgiram diversos insights:
- Volume de Compras: O cluster Insiders representa 58,87% do total de itens comprados.
- Faturamento: Clientes do grupo Insiders contribuem com 53,86% do faturamento total.
- Devoluções: A média de devoluções é maior no cluster Insiders.
- Faturamento Mediano: A mediana do faturamento no cluster Insiders é 781,46 vezes superior à mediana da base geral.
Esses insights ajudam a equipe de marketing a entender o perfil de seus melhores clientes e a planejar ações para potencializar seu relacionamento com a empresa.
6. Deploy e Implementação do Modelo
O destaque do projeto está na etapa de implementação. Para disponibilizar o modelo em produção, foram utilizados serviços da AWS:

- Armazenamento: Criação de um bucket no Amazon S3 para armazenamento de datasets e modelos treinados.
- Banco de Dados: Criação de um Banco de Dados Postegres na Amazon RDS (Relational Database Service) para armazenamento dos dados dos clientes agrupados, disponível para acesso para desenvolvimento de Dashboards em Power BI.
- Instância Virtual na Amazon EC2: computador virtual Linux que acessa os dados e modelos para classificação de novos clientes, realizando as tarefas de modo automático através de agendador de tarefas (CronJob e PaperMill).
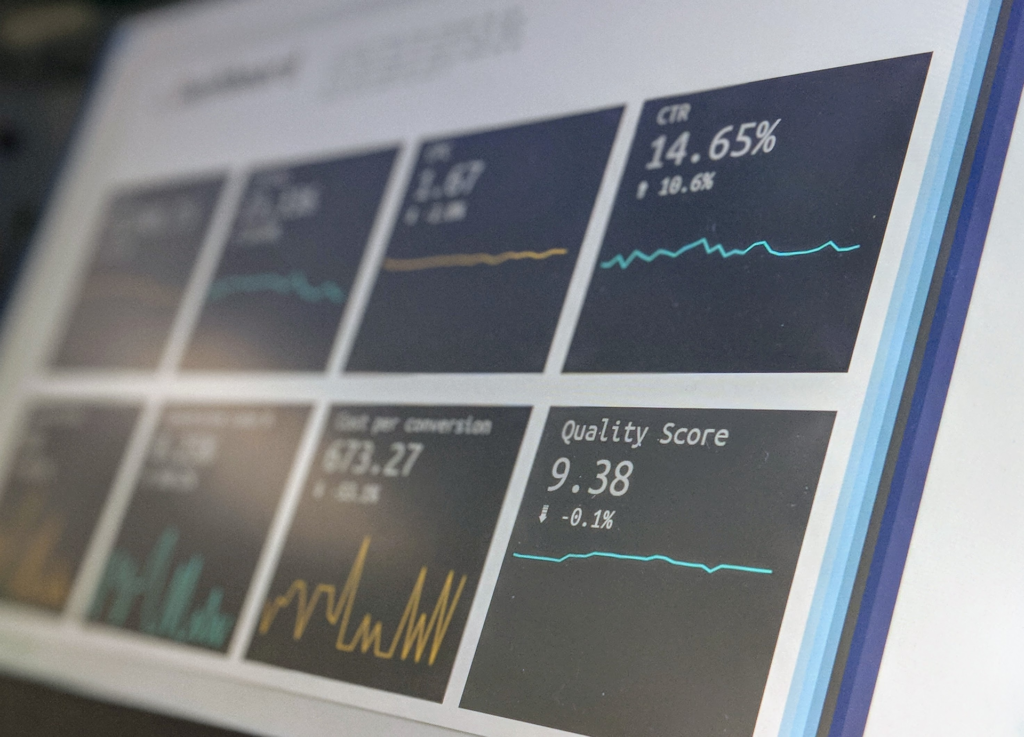
Com o modelo implementado, foram gerados relatórios para responder as necessidades do time de marketing, como no dashboard abaixo:

Se quiser saber todos os detalhes do projeto, incluindo todos os arquivos desenvolvidos, é só acessar meu GitHub.
Conclusão
Com o Programa Insiders, o time de marketing conseguiu um entendimento mais profundo sobre os clientes de alto valor e pôde planejar ações personalizadas e estratégicas para aumentar o faturamento e a fidelização. Esse caso mostra como o uso avançado de dados e machine learning pode transformar a forma como as empresas gerenciam seu relacionamento com os clientes, promovendo um crescimento sustentável e orientado a resultados.